|
|
Lesson 6Let's Party! How 32,256 People Share the Same Optical Fiber |
|
|
For those of you who
may aspire to become a Communications Engineer or design the next
generation of communications products, this is a fun and interesting
lesson. Pay particular attention to the Lab
Experiment(s). The world’s biggest party line To understand the process for mixing hundreds or thousands of voices together it is helpful to consider the modern roadway system. Major roads such as state and interstate highways have uniform on-ramp and exit ramps for getting traffic into and out of the traffic flow, and even local streets have traffic lights to control traffic patterns.
When everything is working properly, the process for mixing incoming cars into flowing traffic is called “interleaving”, meaning every other car on the highway allows an incoming car to merge into the flow. In some cases, small roads merge into slightly larger roads which in turn funnel into superhighways, each with more lanes and designed to operate at higher speeds (unless there is congestion, but don’t get ahead of me). The key concept here is that feeder roads are the slowest of all, and each road they merge into runs at higher speeds and higher capacities Think of the fiber optic transmission system as a superhighway, with similar access points for getting voice, video and data “traffic” on and off the system.
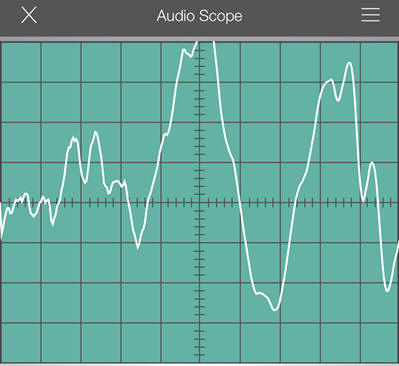
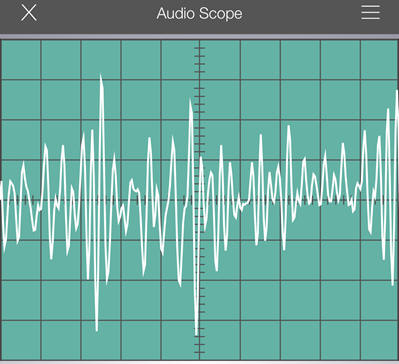
I've Got Your Number Before your voice can mix in with thousands of others it must first be digitally converted to a series of ones and zeros by a process called “Quantizing”. Eight thousand times per second, your voice is sliced up like a loaf of bread, and each sample is measured and converted to a number. The numbers are a series of ones and zeros transmitted to the far end where the process is reversed, converting the incoming numbers back into your original voice signal. To speed the process of quantizing, your voice is acoustically compressed which keeps the quantizing digits in a smaller range. Think of this as having you bend down low to walk through a 3-foot doorway. Once you are through the doorway you stand back up to normal size. At the opposite end of the connection, the quantized digits are reassembled and “uncompressed” to produce a replica of your voice sounds. The study of human voice signals is fascinating and worthy of further examination. The two photos below represent a human voice utting the word "why" and also the letter "s". What are your immediate observations between the two samples?
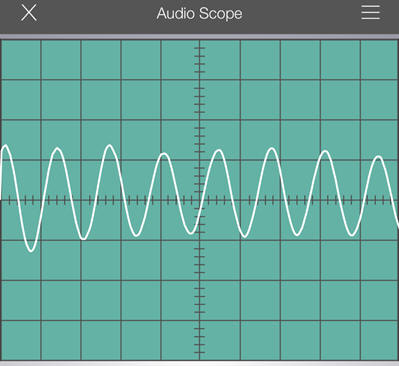
The trace of the word "why" as compared with the letter "s" reveals that our vocal cords, shape of the mouth and position of our teeth work together to create some pretty complex signals. On the left, the word "why" is dominated by lower-frequencies, while the letter "s" on the right is rich in higher-frequency components. In fact, it is also possible to whistle a pure tone that resembes a single frequency as shown below.
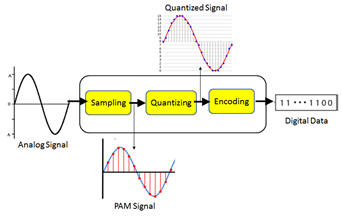
The sounds we utter when speaking vary slightly by language, but are all very similar in the spectrum of frequencies. The quantizing process has no concern as to whether the speech or sound is a specific language, nor even if the sound is intelligible, it merely quantizes whatever sounds are presented and faithfully reproduces them at the distant end. In Lesson 6 Experiments, you will view your own voice signals. There's an App for That The device that quantizes and converts your voice from analog to digital and back to analog is called a CODEC (Coder/Decoder), so there is a CODEC inside your cell phone to convert the voice signals in both directions. For older analog home phones, the CODEC is usually located at the first electronic network element owned by the phone company. The process is: 1. Voice signals are compressed 2. Compressed voice signals are sampled 8,000 per second (Pulse Amplitude Modulation signals) 3. The slivers of voice (PAM samples) are quantized (assigned numbers) 4. The numbers are converted to ones and zeros for transmission
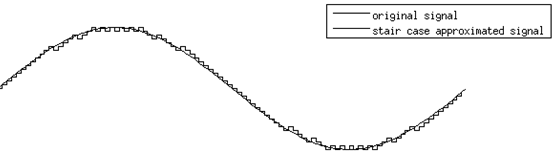
At the far end, the process is merely reversed. However, an additional filter is added at the end, as the process of converting the voice to digital results in "quantizing noise". When the voice signal is reassembled, it exhibits thousands of stair steps as shown below. A low-pass filter removes this noise and smoothes the signal. 1. Ones and zeros are received and converted to Pulse Amplitude Modulated signals 2. Pulse Code Modulated signals are reassembled in order, creates "bumpy" signals 3. Reassembled signal is passed thru a filter for smoothing 4. Replica of distant communication is presented in analog for listener
The system does not distinguish between languages, as it can only quantize whatever sound is presented, so English, Spanish and Chinese get quantized just as easily as a cough or sneeze. There are even new methods for cell phones called “Predictive Encoding” where the processor tries to “predict” what you are saying to speed up the process. If a higher fidelity signal is required (sounds more like your voice), or high-quality music is desired, the standard sample rate of 8,000 per second (8kHz) is increased significanly, such as 48,000 samples per second. Once your voice is digitized, it is sent to an “on-ramp” to join hundreds or thousands of other voice calls, movie downloads, emails, texts, tweets, etc. This process is called “Multiplexing.” Shall we take the train, or jump into the river? There are two predominant methods for transmitting content across optical fibers: Time Domain Multiplexing (TDM); and Packet Transmission (Packet). Both share some processing steps but quickly and radically diverge in technology. We will examine both below. A TDM network can be visualized as pair of trains running between two cities. One train runs from here to there, and the other train runs from there to here. Each train has 24 cargo cars the exact same size, and after the 24th car is another engine with a flag followed by the next 24 cargo cars. This parade of 24 cargo cars followed by a flag, followed by 24 more cargo cars is repeated endlessly.
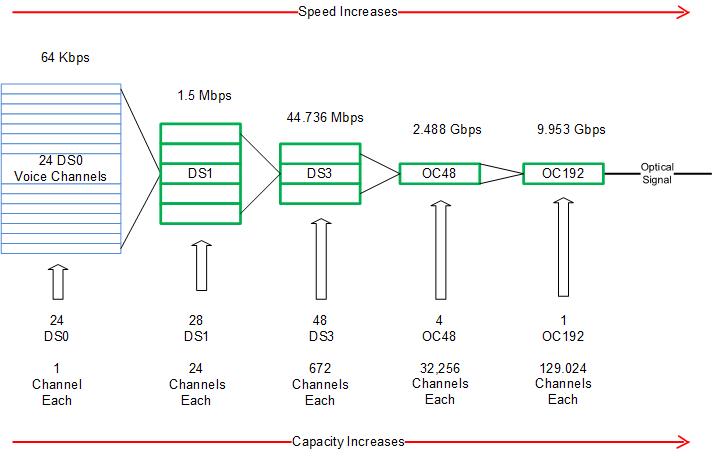
Therefore, each end sends, or transmits train cars to the far end, and receives train cars from the other end. The transmit at location A is the receive at location Z, and the transmit at location Z is the receive at location A. The train cars are all a fixed size, and both trains operate at the exact same speed which must be closely synchronized and monitored. Recall that your voice is sampled 8 thousand times per second, and as the train approaches, the first slice of your voice is deposited in train car #1. Train cars 2 – 24 contain samples of 23 other conversations. After we see the flags, the second sample of your voice is deposited in the first car and this process continues endlessly. The flags represent a system with 24 channels, and the train is running so quickly that your next voice sample is ready just as the next set of 24 cars arrive. The Worlds Biggest Party Line The TDM method was developed in an era where communications networks were used almost exclusively for voice telephone calls. As data needs became popular, processed were developed to “shoehorn” data into the existing voice network with limited success. This called for a new method for transmitting payloads. In the TDM world, capacities are described as the number of DS0 channels supported. As shown below, a DS0 channel supports only a single phone call. The DS stands for Digital Signal Level. When your voice is quantized and digitized, it is inserted first into a DS0, then mixed in with 23 others to form a DS1. The DS1 is then multiplexed (interleaved) with 671 other's to creat a DS3 signal. This is like an automobile continuing a series of on-ramps to higher speed roadways. This multiplexing scheme of interleaving lower speed signals into higher speed systems contines up to OC48 (OC stands for Optical Carrier Level), supporting 32,256 simltaneous phone calls. In the time since we originally presented this material, the numbers just kept climbing, so today SONET systems can support up to 129,024 simltaneous calls.
Now consider that in Lesson 5 we learned that optical fibers have "windows" of bandwidth that allow more than one system to operate on the same fiber without interference, so multiple OC192's can be carried over the same optical fibers. That means a fiber carrying a TDM system can support over half a million calls simultaneously!
In the early days of fiber deployments, systems were based on Asynchronous transmission technolgy, and were basically point-to-point networks. The need for higher numbers of fiber terminations drove a new design in the US telecommunications network called the "Synchronous Optical Network" (SONET). The Europeans developed their own version called Synchronous Digital Hierarchy (SDH). SONET allows for optical transmission systems to be deployed in a ring configurations, creating a self-healing safety net in case of a fiber cut. Ring technology also allowed carriers to build very high-speed networks with multiple on/off ramps as compared to old point-to-point systems. These optical "interchanges" were called Add/Drop Multiplexers (ADM), which allowed smaller users to extract only the circuit speeds and capacities they needed from the high-speed optical highway. The SONET system uses four fibers with two independent transmit and receive paths. The Primary Ring transmitted information clockwise, and the Secondary Ring transmitted information in the opposite direction. If the Primary fibers were cut, traffic was merely accessed from the Secondary Ring. If fibers for both Primary and Secondary were cut at the same time, nodes on each side of the cut merely went into loop mode, so there was no interruption of signal in either direction.
While TDM networks dominated telecommunications networks for 75 years, they were originally designed to haul voice-grade communications around the country. Over the past 30 years a majority of traffic has moved to data and video, with voice consuming a smaller percentage of the network bandwidth. Therefore, new transmission technologies were developed that are much more efficient in transmission of video and data signals. Please Open This Packet While TDM networks operate at specific channel size with no delays and the speeds are the same in both directions, a Packetized Network is more like throwing pingpong balls into a raging river. Let’s go back to the discussion on quantizing and recall that once your voice is quantized, it is immediately inserted into a rail car in the exact order in which it was received. If the system incurs an error it can destroy the integrity of the next several samples until the system resynchronizes and recovers. However, in a packetized network all samples are assigned an address for the final destination as they come into the system. Rather than rely on a fixed, rigid method for delivering information, Packetized Networks relay on sorting and forwarding packets of information based on the addressing, there is no fixed train from one end to the other. Additionally, packetized networks can adapt the packet size to the payload. With TDM, larger payloads had to be broken down to the size of the train car, they could not vary. A packetized network resembles a spider web and each intersecting line has a router which reads the arriving packet addresses and forwards them to the next router as defines by its knowledge of the routes and routers between each end point. Like SONET, a packet network has built-in paths to reduce outages, but the strenght of a packet netwok is that any router can handle any packet, rather than only being able to send it to the next node that is hard-wired to the fiber. While it is true that routers are also connected by fibers, they are able to handle traffic on a higher plane than the physical interface, so if a fiber link goes down between any sites, the entire network becomes aware and can merely route traffic via another logical path. If you drive down the road being directed by a GPS map, an alternative route can be selected for road closings, clogged traffic, etc. In this same manner, packet networks keep track of their own efficiency, rerouting packets many times per second if needed. This is a huge advantage over TDM networks which often require human intervention to reroute traffic in certain situations.
Like the Post Office When you want to send a card or letter to a friend or relative, you place the item in an envelope, provide your return address and the destination of the receiver. Once you deliver the note (packet) to the Post Office, it is validated, sorted and forwarded to the next point toward the final destination. If for some reason it is undeliverable, it is returned to you with an explanation on the error so you can resend the item. Now, what if the post office opened your letter, and sent each word to the final destination by creating a new envelope which contained only a single word from your note, but provided a code to identify which line and word to reassemble the full letter at the far end? Now your letter is possibly a few hundred packets, all with addresses and coding instructions. If for any reason some can’t be delivered, they are returned to you for retransmission. So, while a TDM network operates like a train, a packetized network is like assigning addresses to a million ping pong balls and tossing them into a raging river. As the ping pong balls arrive at tributary’s, a router sorts them, passing each packet to the best route to the final destination.
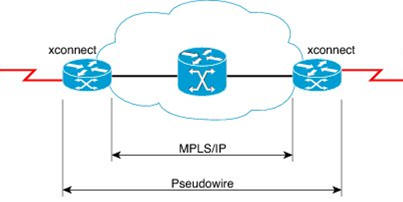
Packet Networks have the opposite problem as TDM networks. Whereas TDM networks were designed for voice traffic, Packet Networks were designed for data traffic, so for all non-delay-sensitive services they are extremely efficient and reliable. However, delay-sensitive services like voice calls and live video require special methods to “reserve bandwidth” or create the equivalent of a TDM pipe inside the packet network. The process for creating a TDM “pipe” in a packetized network is called “Pseudo-Wire Emulation" (PWE). Without pseudo-wire emulation, voice calls could not be transmitted over a packetized network, as the result would be a bunch of babble at both ends. Newer methods for delivering live voice and video are under development, and the quality of voice and video over packet connections has greatly improved over the past decade.
To Delay or Not to Delay Your voice is one of the few things that need to be digitized for transmission on a TDM or Packet network as many other communications media are already digital. For example, when you depress a letter or number on a keyboard, this generates a digital code that represents the character pressed. Likewise, text messages, tweets, stored movies, and MP3 music files are also ready for transmission with no CODEC required. As you consider all types of media, how many require instant transmission with no delay? Certainly, your voice must be delivered with no delay or variation, or the resulting sounds at the opposite end would have many clicks or missing syllables. Likewise, full-motion video like videoconferencing must have no delay or the picture would pixelized or drop out frequently. However, email, texts, and stored music or movies could have some variations with no loss of quality because by the time you read or listen to them, the entire content has already arrived and stored. For example, if you download a movie tonight to watch later, who cares if the process is slow and jerky so long as all the data eventually gets loaded to your hard drive and available by the time you view the material? And emails are not instantaneous like voice, so what does it matter if some letters get delayed for a few milliseconds if they have all arrived when you open the email? This is a key point, as some types of media we transmit are “Delay-Sensitive”, and some are “Non-Delay-Sensitive”. Traditional TDM networks did not suffer varying delays of transmission. However, the nature of packet networks is to have variable delays in transmission of content, and the delay may be different in each directions to/from the far end. For most content this is not a problem.
The key point here is that packet networks can handle both delay-sensitive and non-delay-sensitive communications. To eliminate delays, packets are assigned priorities with special labels that "reserve bandwidth", meaning they are passed at the expense of other traffic which is non-delay-sensitive. When properly designed, both types of networks provide quality, reliable communciations for all types of payload including voice, video and data. Each have their own vulnerabilities, some of which have been highly publicized. Older TDM networks were always described by the equivolent number of phone calls they could support. However, with packet networks, the emphasis is on pure bandwidth, so a really fast network would be rated at 100 Gbps (Gigabits per second, or one billion bits per second). Other speeds are 10 & 40 Gbps. The Ethernet connections in your home were once 10 Mbps (Megabits per second, or one million bits per second), then "Fast Ethernet" raised that to 100 Mbps. Today almost all Ethernet equipment can support 10/100/1000 Mbps. Some units say 1000 Mbps, others say 1 Gbps but these are just the same speeds described in Magabits and Gigabits. Lab studies have achieved Terabit speeds that may some days find use in high-density netwok corridors. Can I Hear You Now? So, whether TDM or Packetized, your voice does indeed join up to a half million others in an optical fiber. Some manufacturers claim this could top a million with the latest technology. However, in modern systems only a fraction of the traffic is voice, as most payloads are some form of video or data such as text, email, tweets, web browsing, etc. Consider that when you use a web browser to access your bank account or provide credit card info for purchases, all that info flows at some point across a fiber optic facility. Since we are all in there together, can I listen in on your conversation, view your web pages or read your email? Can I steal your PIN? Relax, as the answer is a qualified no. As another user in the same optical fiber, there is no way for me to "tune" into your communications, nor can you access mine. As we stated in the Tutorial Opening, you are more likely to be overheard or have your information stolen from someone standing nearby on a train, airplane or restaurant. This completes Lesson 6 Let's Part! How 32,256 People Share the Same Optical Fiber OK, now crank up your investigative skills and conduct the Lab Experiment (s) for this lesson by clicking the button at the top right of this page, then proceed to the Lesson Test by clicking the button also at the top right of this page. Don't forget you can order a sample fiber from a real telephone cable for use in some experiments by clicking ORDER FIBER or the button on top right of the Home page. Prices from $1.00 per fiber. Great way to earn extra credits in your next Technical Presentation, Science Fair or Merit Badge! |
|
| ©2012 ©2019 dB Levels, Inc. All Rights Reserved |